How to Configure and Connect the Simba Spark JDBC Driver with SQLLine

Simba Apache Spark ODBC and JDBC Drivers efficiently map SQL to Spark SQL by transforming an application’s SQL query into the equivalent form in Spark SQL, enabling direct standard SQL-92 access to Apache Spark distributions. The drivers deliver full SQL application functionality, and real-time analytic and reporting capabilities to users.
In this blog, we’ll walk you through configuring and connecting the Simba Spark JDBC driver with SQLLine Documentation.
You can follow the same process with any Simba JDBC driver.
Prerequisites
Apache Spark versions 1.1 through 2.3.0.
SQLLine
SQLLine is a command-line shell for issuing SQL to relational databases via JDBC. You can read more about SQLLine in their manual.
Installing SQLLine
Installing and building the SQLLine package from source:
git clone https://github.com/julianhyde/sqlline.git cd sqlline mvn package
SQLLine can be run with the following command:
java {-Djava.ext.dirs=sqllinedir} {sqllinedir/sqlline.jar} [options...] [properties files...]
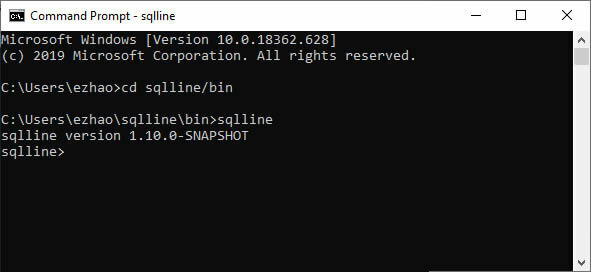
Or running from your installed folder and verifying SQLLine with version number. Once you have started SQLLine, you will see a prompt that reads “sqlline> ”
Installing Simba Spark JDBC Driver
Check system requirements first.
Download a free evaluation of the Simba Spark JDBC Driver. Unzip and put the driver JAR files into the target folder of the SQLLine installation folder, where the source build placed its JAR files.
Example: Make sure the Simba JDBC Driver SparkJDBC41.jar is in $INSTALLEDPATH\sqlline\target
Get the evaluation license file from your email and place that in the same folder as the jar file.
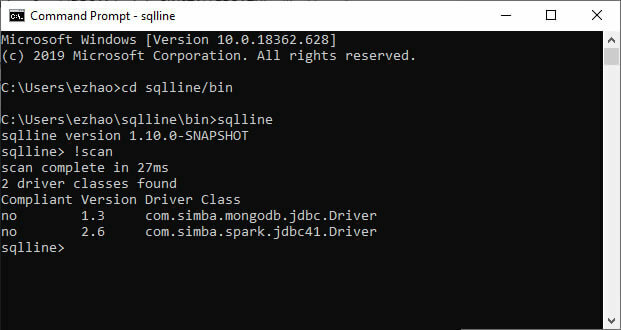
SQLLine does not need you to specify the CLASSPATH for the drivers if you put the JAR files in the right place. You can use command !scan to verify the list of installed drivers.
Connection
Set the connection string example:
jdbc:spark://localhost:11000/default2;AuthMech=3;UID=simba;PWD=simba
You can specify optional settings such as the schema to use or any of the connection properties supported by the driver. For a list of the properties available in the driver, see Driver Configuration Options. If you specify a property that is not supported by the driver, then the driver attempts to apply the property as a Spark server-side property for the client session.
To connect to a Spark server, you must configure the Simba Spark JDBC Driver to use the authentication mechanism that matches the access requirements of the server and provides the necessary credentials. To determine the authentication settings that your Spark server requires, check the server configuration and then refer to the corresponding section below.
Spark Thrift Server supports the following authentication mechanisms:
- Using No Authentication
- Using Kerberos
- Using User Name
- Using User Name And Password (LDAP)
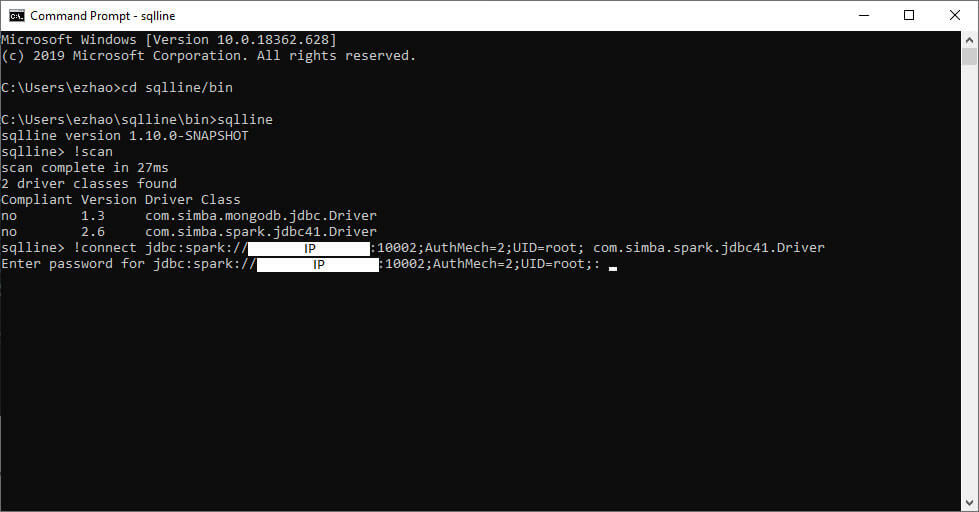
Perform the connection
Sqlline> !connect jdbc:spark://000.000.000.000:10002;AuthMech=2;UID=root; com.simba.spark.jdbc41.Driver
Verify connection
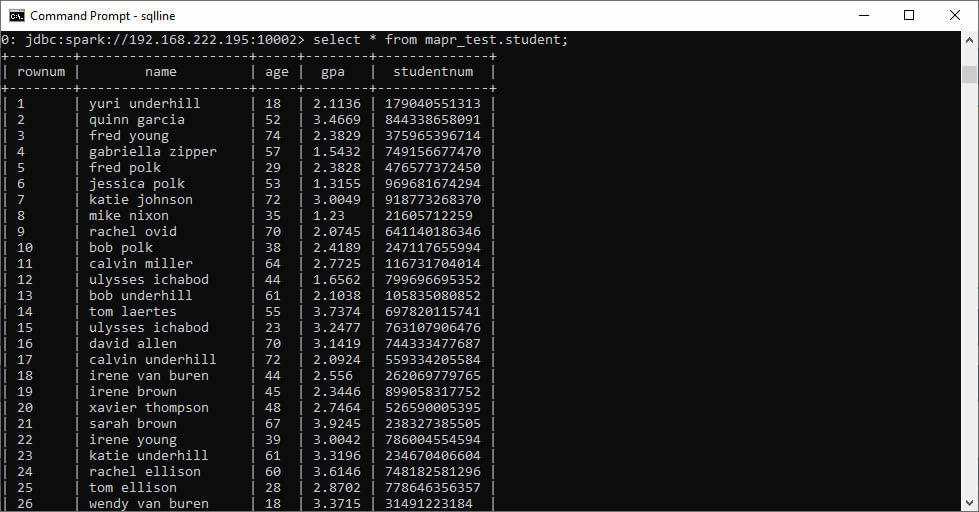
Use the “!tables” command at the SQL prompt to get a list of tables.

Perform a select query to verify the connection.
Things to watch out for
Simba drivers support six (6) levels of logging. If you are debugging an issue with Magnitude Simba support, we will frequently ask you for Trace logs to aid in reproducing the issue.
To enable the TRACE log, simply specify LogLevel and LogPath in the connection string.
Example:
jdbc:spark://localhost:11000;LogLevel=3;LogPath=C:\\temp
That’s it. You’ve now connected the Simba Spark JDBC Driver with SQLLine
Learn also how to connect Power BI to a SQL server analysis services database.
To learn more, please visit our Resources.